
PROJECT
THE PROJECT
Objectives
The proposed research aims at enhancing our understanding of how aspects of speakers’ grammars, especially those influenced by extra-grammatical factors, can be computationally modeled.
The project aims to:
- Explore differences in stress grammars between children and adults by producing a body of experimental data that will shed light on unknown aspects of Greek acquisition.
- Construct a probabilistic computational model, based on Smolensky & Goldrick’s (2016) Gradient Harmonic Grammar (GHG), to simulate biases shaped by lexicostatistic frequencies and age-dependent factors. This grammar-informed GHG algorithm will be tested against grammatically naïve algorithms, such as Machine Learning Classifiers, in order to compare their performance to actual stress choices made by children and adults.
- Develop an annotated for Part-of-Speech version of a school-aged children corpus (Helexkids database, Terzopoulos et al. 2017) to be used for estimating children’s vocabulary growth.
- Create a Wordtool with 100 most frequent Helexkids words to be used by educators in designing language material and activities for children.
Research Questions
Are there significant differences between the lexical/non-canonical nominal stress grammar of primary school children and that of adults in Greek?
WP1 – The experimental research
To delve into the intricacies of early grammars, we plan to conduct production experiments on two groups of primary education students (G1: Grades 2–3 Grade, G2: Grades 4–6). The same experiments will also be conducted to a group of adults (G3, 18–40 years old). The comparative approach will allow us to identify any potential differences between the internal knowledge of children and adults.
Each group will consist of 30 participants, totaling 90 monolingual speakers of Greek participating in the experimental tasks.
The collaborating schools will be announced shortly.
Expected key result: Uncovering differences in stress grammars between children and adults.
A note on Ethics
Ethical consideration is given to all aspects of the GRADIENCE project adhering to the principles of the Ethics Committee of the host institution.
The project has been granted the AUTH Ethical Approval by the Aristotle University of Thessaloniki Code of Ethics in Research Committee (Protocol No 195171/2023 & 50149/2024) and the detailed regulations may be found here.
Are there biases in the young Greek speakers’ productions? Do young speakers’ productions reflect lexicostatistic stress frequencies or not?
WP2 – Developing tools for estimating lexicostatistical stress frequencies
In order to investigate whether word frequencies in school-aged children’s vocabularies affect their stress production patterns, we will check for correlations between productions of speakers from each group with lexicostatistic stress frequencies. These frequencies will be extracted from existing age-specific databases (such as Helexkids, Terzopoulos et al. 2017, and A-Clean, Apostolouda 2018, based on Protopapas et al. 2012), that will be appropriately annotated for Part-of-Speech (PoS).
Expected key result: Uncovering the impact of lexicostatistic word frequencies on young speakers’ stress productions. (“The Lexicon can/may shape children’s grammars.”)
How can a grammatical model capture speakers’ stress tendencies?
WP3 – Constructing a probabilistic grammar for Greek nominal stress
To model the probabilistic distribution of stress among Greek nouns across the three speaker groups, we will implement the following workflow:
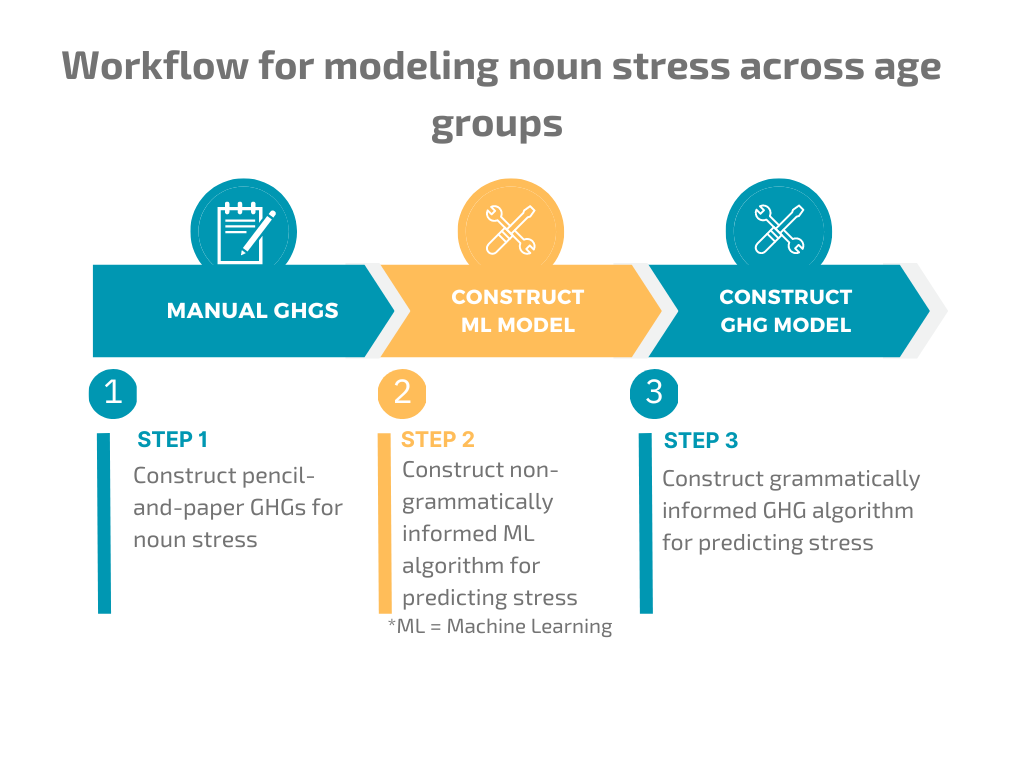
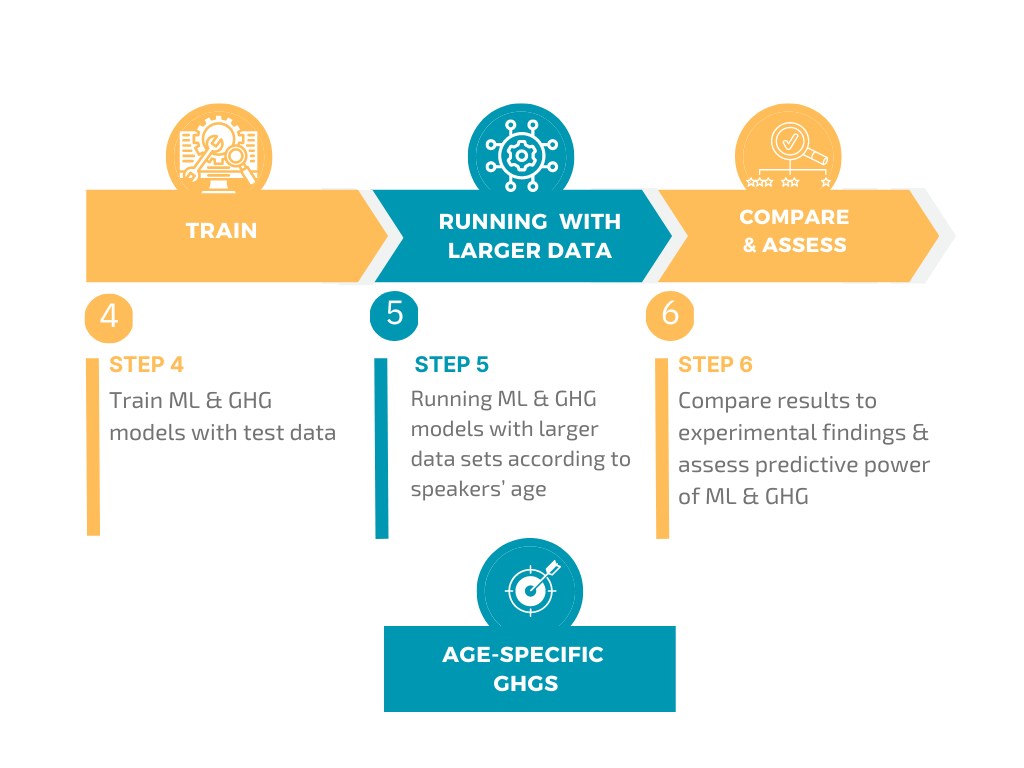
Expected key result: The construction of a GHG for the three age groups, with the factor of lexical frequency appropriately integrated into the grammatical system.
Innovation
Delivering a comprehensive computational framework for lexical stress that is easily understandable and adaptable by other branches of cognitive science.
Improving our understanding of the computational architecture of cognition and decision-making, thereby contributing to the broader fields of machine learning and deep learning technologies.